Overview
Motivations for Caching of HTTP Resources
The basic idea of HTTP caching is to make network usage more efficient and to reduce the load on webservers by storing resources that have been requested from a webserver in a “cache”, and if user agents request the same resource, and if the result of that request would be equivalent to the result of the last request of that resource, serving that resource from the cache.
The caching of HTTP resources can also involve transformation or requests and replies, such as redirections, downsampling of media content or malware scanning and removal.
Such additional tasks that can be assigned to “caching” of HTTP resources reflect the traditional function of HTTP as content transfer for publications. If a downsampled representation of a media resource fulfils the intention of the publication “in no way worse” than the original representation (for example, because the targeted output device could not present the resource in a higher resolution anyway), the downsampled representation is deemed sufficient for the purposes of the publication.
Components of HTTP-Caching Systems
In the following, a web client program operated by a user, be it a command-line client such as “curl”, a web browser such as “firefox” or a tool with HTTP client functions such as “apt” are all called “User Agents”.
Programs that have the purpose of storing resources rendered by web servers for caching are called “Caches”.
A “webserver”, for the purpose of this text, is an authoritative source for the retrieval of certain resources via HTTP. More precisely, a webserver is a server process that generates the original, non-cached version of a resource that is identified by an URL protocol://server:port/uri if a web client contacts a network address of server on port port (tcp) using protocol protocol (which can be “http” or “https”) and requesting uniform resource identifier uri.
A cache is said to be “intermediate” if it operates separately from the user agent, if its users are clients which can be user agents or other caches and if, for the purpose of responding to client requests, performs requests to servers, which can be other caches and webservers.
For the purposes of this text, a cache is said to be “public” if it can be used by multiple user agents. A public cache is said to be “shared” if the same instance of a cached resource can be accessed by multiple user agents. On the opposite, a cache is said to be “private” if it can only be accessed by a single user agent.
Examples: An intermediate cache that is configured for access by the web browser of only a single workstation is not necessarily private, because it could potentially be accsseed by all users of that workstation. A non-intermediate cache that is built into a specific web browser installed on the workstation, where the web browser takes adequate steps to compartmentalize access to the cache per user is a private cache.
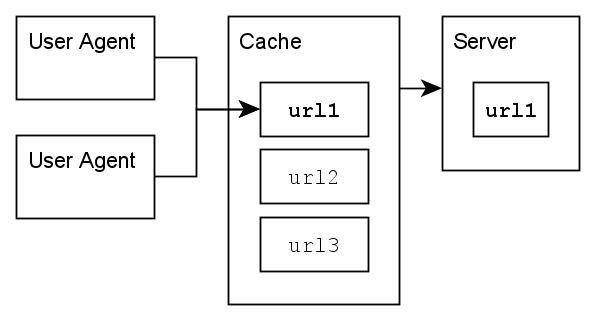
Shared intermediate HTTP caching.
Intermediate caches are often implemented as web proxies (see below), they act as HTTP servers towards user agents and as HTTP clients towards webservers.
IETF Specifications
HTTP headers (in requests and responses) and response status codes are used by HTTP clients and servers to control the caching of resources. For HTTP version 1.1 these are specified in [RFC 7231]. For HTTP version 2 these are specified in [RFC 7540].
[RFC 7234] specifies caching mechanisms in detail, giving further explanation about HTTP headers and response status codes.
Information about caching-related expectations from HTTP methods can be found in [RFC 7231], section 4.2.3 (Cacheable Methods) and subsections of section 4.3 (Method Definitions) and section 6 (Response Status Codes).
[RFC 7232] specifies conditional HTTP requests, which can be utilized for efficient cache updates.